Este artículo es el tercero de una serie de artículos publicados por la startup IA Sapiens dedicada a explicar qué es la Inteligencia Artificial en el sector porcino. En el artículo anterior, hablamos sobre lagos de datos e inteligencia empresarial. En este, daremos un paso adelante y comenzaremos a hablar de Inteligencia Artificial y de modelos predictivos.
Inteligencia Artificial
 Si buscamos una definición oficial de inteligencia artificial, veremos que está relacionada con conseguir que las máquinas hagan cosas que hasta hace poco se pensaba que estaban reservadas a los humanos, muchas de ellas a sus sentidos. Por ejemplo, ser capaces de ver, o de escuchar, o de escribir, o de conducir!. Estas actividades eran hasta hace relativamente poco tiempo inasumibles para las máquinas, pero mejoras en la capacidad de computación y almacenamiento, y evoluciones realmente brillantes desde el punto de vista matemático y de las ciencias de la computación, han hecho que cualquier adolescente con su portátil pueda crear una IA que sea capaz, por ejemplo, de solucionar los problemas de sus deberes, o de reconocer el vídeo de su webcam para generar una versión del mismo en estilo cómic.
Si buscamos una definición oficial de inteligencia artificial, veremos que está relacionada con conseguir que las máquinas hagan cosas que hasta hace poco se pensaba que estaban reservadas a los humanos, muchas de ellas a sus sentidos. Por ejemplo, ser capaces de ver, o de escuchar, o de escribir, o de conducir!. Estas actividades eran hasta hace relativamente poco tiempo inasumibles para las máquinas, pero mejoras en la capacidad de computación y almacenamiento, y evoluciones realmente brillantes desde el punto de vista matemático y de las ciencias de la computación, han hecho que cualquier adolescente con su portátil pueda crear una IA que sea capaz, por ejemplo, de solucionar los problemas de sus deberes, o de reconocer el vídeo de su webcam para generar una versión del mismo en estilo cómic.
Llegar hasta aquí ha sido un largo camino, donde mucha gente ha aportado su granito de arena para hacer avanzar esta disciplina, y donde nuevos avances como las arquitecturas basadas en Transformers (escribo este texto en Agosto del 2023), un tipo de arquitectura de Inteligencia Artificial, nos hacen pensar que esta revolución no acaba sino de comenzar. De hecho, a nivel personal, puedo decir que nunca pensé que vería en mi edad adulta un sistema como ChatGPT funcionando. Pensaba que era algo que se alcanzaría tarde o temprano, pero como comportamiento emergente de una AGI (una inteligencia artificial general, una consciencia creada dentro de un ordenador), nunca como resultado de una arquitectura básica basada en Transformers, y que sería algo que tardaría décadas en llegar.
Un ejemplo de Inteligencia Artificial es el conteo de lechones mediante Vision Computer (la parte de la IA que tiene que ver con el procesamiento de vídeo). Por ejemplo, en la imagen podemos ver un sistema que mediante una webcam es capaz de contar los cerdos que están siendo descargados. Pero… ¿Cómo funciona por dentro esta caja negra? ¿Cuál es la magia que es capaz de reconocer entre los píxeles de una imagen un cerdo, y es capaz de llevar un conteo de cuántos diferentes han pasado por allí?
Modelos predictivos y aprendizaje
 Imaginemos que tenemos unos datos como los que muestro a la derecha. Como podemos ver, tenemos dos series de datos, X e Y, que parecen estar relacionadas. Por ejemplo, X podría ser el volumen de kilos de cerdo de una nave, e Y podría ser la cantidad de metano o CO2 que emiten. Queremos construir una función que nos ayude a estimar el metano emitido, es decir, que nos ayude a relacionar de alguna manera X con Y. Al menos, esa es nuestra intención, nuestra hipótesis. Es posible que realmente no haya ninguna relación entre los kilos presentes y el metano emitido, o es posible que esta relación sea mucho más compleja y haya otros factores involucrados cuyos datos no hemos conseguido identificar o recoger. También es posible que estos datos no sean del todo correctos. Quizás al recogerlos los sensores no funcionaban correctamente, durante todo o parte del experimento. En todo caso, este es un ejemplo con muy pocos datos, normalmente recogeremos muchos más datos para construir modelos fiables! También es posible que haya muchos modelos posibles y buenos para explicar esta relación, y que tengamos que elegir uno basándonos en criterios más discrecionales. Estos son problemas típicos a resolver a lo largo de un proyecto de inteligencia artificial, sea en el sector porcino o en cualquier otro sector.
Imaginemos que tenemos unos datos como los que muestro a la derecha. Como podemos ver, tenemos dos series de datos, X e Y, que parecen estar relacionadas. Por ejemplo, X podría ser el volumen de kilos de cerdo de una nave, e Y podría ser la cantidad de metano o CO2 que emiten. Queremos construir una función que nos ayude a estimar el metano emitido, es decir, que nos ayude a relacionar de alguna manera X con Y. Al menos, esa es nuestra intención, nuestra hipótesis. Es posible que realmente no haya ninguna relación entre los kilos presentes y el metano emitido, o es posible que esta relación sea mucho más compleja y haya otros factores involucrados cuyos datos no hemos conseguido identificar o recoger. También es posible que estos datos no sean del todo correctos. Quizás al recogerlos los sensores no funcionaban correctamente, durante todo o parte del experimento. En todo caso, este es un ejemplo con muy pocos datos, normalmente recogeremos muchos más datos para construir modelos fiables! También es posible que haya muchos modelos posibles y buenos para explicar esta relación, y que tengamos que elegir uno basándonos en criterios más discrecionales. Estos son problemas típicos a resolver a lo largo de un proyecto de inteligencia artificial, sea en el sector porcino o en cualquier otro sector.
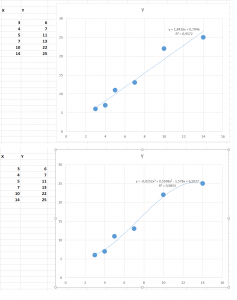 Por ejemplo, un modelo predictivo que explica bastante bien la relación entre X e Y en este caso es la recta y= 1,8426x + 0,7946. Cuando la pintamos sobre los puntos de nuestro experimento, vemos que todos los puntos de nuestros datos están cercanos a la línea. Los científicos de datos dirán que tiene un R2 de 0,9572, que es una medida entre 0 y 1 de cómo de buena es esta recta para explicar la relación entre X e Y…. es muy buena! Pero no es la única posible, por ejemplo la exponencial de grado 2 todavía es capaz de explicar aún mejor la relación… al menos con los datos que tenemos en estos momentos!
Por ejemplo, un modelo predictivo que explica bastante bien la relación entre X e Y en este caso es la recta y= 1,8426x + 0,7946. Cuando la pintamos sobre los puntos de nuestro experimento, vemos que todos los puntos de nuestros datos están cercanos a la línea. Los científicos de datos dirán que tiene un R2 de 0,9572, que es una medida entre 0 y 1 de cómo de buena es esta recta para explicar la relación entre X e Y…. es muy buena! Pero no es la única posible, por ejemplo la exponencial de grado 2 todavía es capaz de explicar aún mejor la relación… al menos con los datos que tenemos en estos momentos!
Otro punto importante aquí, es que solo estamos utilizando una única variable X, para predecir la variable Y. Pero normalmente, la realidad es mucho más compleja, y para explicar bien una variable Y, vamos a necesitar varios factores (variables, columnas). Por ejemplo, podríamos completar nuestro modelo de emisiones de metano con medidas sobre la temperatura y la humedad. Entonces tendríamos 3 columnas X{x1, x2, y x3}, para cada uno de los tres factores que esperamos expliquen el comportamiento del metano. Al haber pasado a tener tres factores, tenemos un pequeño problema adicional: los seres humanos estamos limitados en el número de dimensiones que podemos visualizar, por lo que ya no es tan fácil pintar en una gráfica cada una de las filas de nuestra Excel como un punto. Podemos por ejemplo pintar x1 contra y, x2 contra y x3 contra y. Pero visualizar cómo se mueven x1, x2 y x3 contra y escapa de nuestras capacidades visuales. Aunque existen métodos matemáticos para intentar superar nuestras dificultades, cada vez más vamos a tener que ir introduciendo técnicas de programación (en Python, R, u otros lenguajes), que escapan a lo que una hoja Excel es capaz de hacer.
Machine Learning
 Estos modelos de los que estamos hablando pertenecen a una rama de la inteligencia artificial que se llama Machine Learning. En castellano se traduce como aprendizaje automático. Su nombre significa que la fórmula que hemos obtenido (en este ejemplo y= 1,8426x + 0,7946), no la hemos deducido matemáticamente, sino que la hemos aprendido gracias a los datos. Estos algoritmos aprenden en base a ir ajustando los parámetros de la fórmula (en este caso 1,8426 y 0,7946), hasta que encuentran la que mejor se ajusta a los datos observados. Esta fase de aprendizaje se llama entrenamiento (training), y una vez que tenemos la fórmula y comenzamos a usarla esta fase se llama predicción (scoring).
Estos modelos de los que estamos hablando pertenecen a una rama de la inteligencia artificial que se llama Machine Learning. En castellano se traduce como aprendizaje automático. Su nombre significa que la fórmula que hemos obtenido (en este ejemplo y= 1,8426x + 0,7946), no la hemos deducido matemáticamente, sino que la hemos aprendido gracias a los datos. Estos algoritmos aprenden en base a ir ajustando los parámetros de la fórmula (en este caso 1,8426 y 0,7946), hasta que encuentran la que mejor se ajusta a los datos observados. Esta fase de aprendizaje se llama entrenamiento (training), y una vez que tenemos la fórmula y comenzamos a usarla esta fase se llama predicción (scoring).
Redes neuronales y Deep Learning
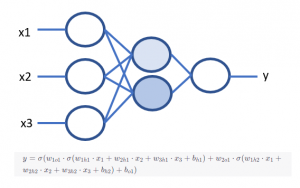 Si te estás preguntando cuantas variables podemos analizar a la vez… pues la respuesta es que muchas, decenas de miles o más! Los Algoritmos de Vision Computer (procesamiento de video), STT/TTS (Sonido) o NLP (Texto), que son modelos predictivos más avanzados, utilizan a veces decenas de miles de variables de entrada. Su manera de aprender también es un poco diferente, aunque siguen basándose en aprender de los datos, utilizan otro tipo de técnicas más sofisticadas. Por ejemplo, normalmente en estos casos se utiliza una manera de aprender la fórmula final, basada en redes neuronales, como la imagen de la derecha. Se les llama redes neuronales por analogía a cómo están conectadas las neuronas de nuestro cerebro. Aunque nuestras neuronas cumplen otras muchas funciones: Que lo llamemos redes neuronales está muy lejos de poder decir que estemos creando una especie de cerebro, estamos simplemente definiendo una fórmula muy pero que muy compleja, pero de una manera que la hace idónea para aprender de los datos observados.
Si te estás preguntando cuantas variables podemos analizar a la vez… pues la respuesta es que muchas, decenas de miles o más! Los Algoritmos de Vision Computer (procesamiento de video), STT/TTS (Sonido) o NLP (Texto), que son modelos predictivos más avanzados, utilizan a veces decenas de miles de variables de entrada. Su manera de aprender también es un poco diferente, aunque siguen basándose en aprender de los datos, utilizan otro tipo de técnicas más sofisticadas. Por ejemplo, normalmente en estos casos se utiliza una manera de aprender la fórmula final, basada en redes neuronales, como la imagen de la derecha. Se les llama redes neuronales por analogía a cómo están conectadas las neuronas de nuestro cerebro. Aunque nuestras neuronas cumplen otras muchas funciones: Que lo llamemos redes neuronales está muy lejos de poder decir que estemos creando una especie de cerebro, estamos simplemente definiendo una fórmula muy pero que muy compleja, pero de una manera que la hace idónea para aprender de los datos observados.
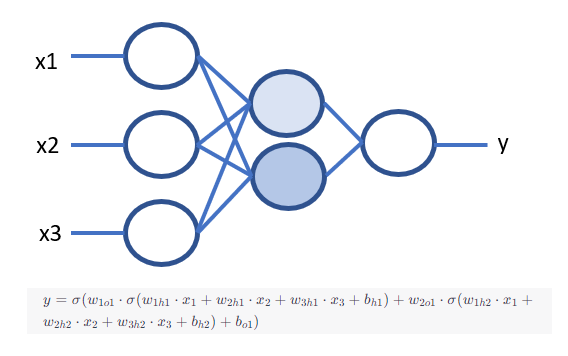
Como puedes ver, la fórmula que nos permite crear esta red neuronal es muy compleja, a pesar de tener sólo 6 «neuronas». Tiene otras características muy importantes como que es capaz de presentar bien no linealidades (concepto en el que no entraremos), y que su estructura basada en capas parece reflejar bastante bien el comportamiento en forma de muñecas chinas del universo en su conjunto (otro concepto en el que no entraremos). Imagina cómo de complejas pueden ser estas fórmulas cuando la red neuronal tiene millones, o trillones, de estas neuronas! En ese caso hablamos de Aprendizaje profundo (Deep Learning). El término profundo aquí hace alusión a que hay muchas neuronas en las capas intermedias (las coloreadas), en las capas más profundas de la red neuronal. Con estos modelos de deep learning vamos a poder hacer cosas realmente interesantes, como predecir la salud de una nave de cebo en base al sonido ambiente, o estimar el bienestar animal de un lechón siguiendo su trayectoria a través de una webcam, pero eso lo veremos posteriormente.
Este artículo es el tercero de una serie de artículos publicados por la startup IA Sapiens dedicada a explicar qué es la Inteligencia Artificial en el sector porcino. En el siguiente artículo, intentaremos ponernos en la piel de los científicos de datos, para entender la metodología de un proyecto de Inteligencia Artificial en el sector porcino.



